
Info N테크 뉴스
소비 취향의 다양성과 서브컬처 Vol. 34
캐릭터 일관성 유지에 성공한 이미지 생성 AI 기술
이미지 생성 AI가 콘텐츠산업에 도입되어 제작 효율성을 높이고 있다. 한 가지 걸림돌은 웹툰이나 애니메이션 등에 필요한 캐릭터 이미지의 일관적인 생성이 힘들다는 것이었다. 하지만 이 문제도 집단 지성에 기반한 ‘디퓨전 프로세스’ 기술의 발전으로 빠르게 해결되고 있다.
 소이.랩의 AI 인플루언서 MIKI 생성 과정
소이.랩의 AI 인플루언서 MIKI 생성 과정
생성형 AI의 시작, 스테이블 디퓨전
2022년 8월, 생성형 AI 기업 스태빌리티 AI는 텍스트 기반 이미지 생성 모델인 ‘스테이블 디퓨전(Stable Diffusion)’을 공개했다. 스테이블 디퓨전의 등장에 따라 이미지 생성 AI 모델에 대한 관심이 급증하고, 이를 효율적으로 실행하기 위한 고성능 그래픽 처리 장치(GPU)에 대한 수요도 함께 증가했다. 특히 엔비디아의 GPU는 이미지 생성 AI 모델의 학습과 추론에 최적화되어 있어 수요가 크게 늘어났다. 이러한 변화는 다른 주요 IT 기업들에게도 영향을 미쳤다. 이처럼 AI 기술의 빠른 발전과 도입은 우리의 일상과 산업 전반에 큰 변화를 가져오고 있다. 하루가 다르게 매일 새로운 기술과 서비스가 등장하는 탓에 마치 <오즈의 마법사> 속 주인공이 된 듯한 착각이 든다.
 최초의 ‘스테이블 디퓨전’ 화면
최초의 ‘스테이블 디퓨전’ 화면
일관된 이미지를 구현해주는 디퓨전 프로세스
노이즈를 넣으면서 이미지를 계속해서 파괴하고, 파괴된 노이즈에 대한 패턴을 기억하면서 그 노이즈 안에서 원하는 이미지를 찾는 것을 ‘디퓨전(diffusion) 프로세스’라고 한다. 최초의 디퓨전 프로세스는 단순히 일관된 결과물을 만들기 위해 설계된 기술이 아니었다. 이 기술은 노이즈를 제거하며 점진적으로 이미지를 복원하는 과정에서, 의도치 않은 결과물의 우연성을 탐구하고 이를 창의적으로 활용하려는 시도에서 출발했다. 글로벌 개발자들은 초기 디퓨전 모델이 가진 한계를 해결하기 위해 공동으로 더 정교한 학습 방법을 개발하고 공유함으로써 해결 방법을 찾아내기 시작했다. 그 목표 중에는 캐릭터의 일관성을 유지하거나 특정 스타일의 이미지를 반복적으로 생성하는 데 필요한 기술이 포함되어 있었다. 컨트롤넷(ControlNet)과 DiT 같은 기술은 이런 연구 과정에서 탄생한 대표적인 결과물로, 이미지의 연속성을 연출하는 데 매우 큰 역할을 담당하게 된다.
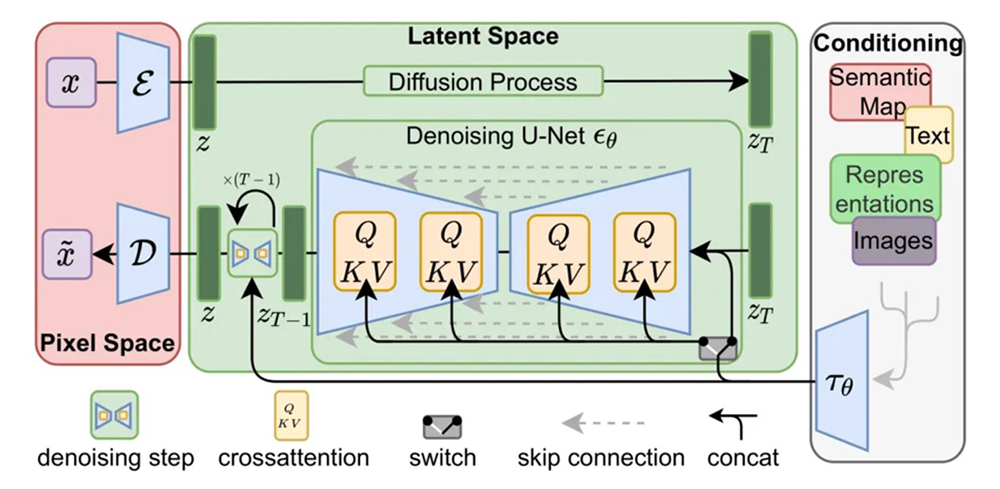 디퓨전 프로세스를 표현한 그래픽
디퓨전 프로세스를 표현한 그래픽
AI 기술 대중화와 함께 늘어난 일관된 이미지 생성 요구
AI 오픈소스 커뮤니티의 활발한 활동은 디지털 콘텐츠 제작의 새로운 지평을 열었다. 특히 엔비디아 RTX 4090 같은 고성능 그래픽 카드의 보급은 일반 사용자들도 집에서 고해상도 이미지와 영상을 생성할 수 있는 환경을 마련했다. AI 기술이 급속히 대중화하면서 인물 이미지의 연속성을 유지하기 위한 커뮤니티의 요구는 다양한 기술적 도전을 촉발시켰다. AI 모델이 동일한 캐릭터의 특징을 유지하면서 연속적으로 이미지를 생성하거나 영상 프레임을 자연스럽게 이어가는 기술이 그 예다.
이러한 커뮤니티 중심의 발전은 상업적 서비스로 확장되어 어도비의 ‘파이어플라이’나 ‘미드저니’ 등의 이미지 생성 서비스와 ‘런웨이 젠3’, ‘클링’ 등의 영상 생성 서비스 그리고 ‘수노’라는 음악 생성 서비스 등을 탄생시켰다. 이러한 상업적 서비스는 개인 사용자뿐만 아니라 영화 제작, 광고, 게임 산업 등 다양한 분야에서 채택되며 AI 기술의 실질적 가치를 입증하고 있다.
일관된 이미지와 영상 구현은 왜 어려운가
디퓨전 프로세스는 숫자와 수학적 확률로 이뤄져 있다. 인간이 프롬프트에 입력하는 문장은 AI 모델에게는 숫자와 벡터로 변환되어 제공된다. 마찬가지로 이미지 역시 픽셀 데이터가 숫자로 변환되어 학습과 추론에 활용된다. 이 과정을 통해 AI 모델은 입력 데이터를 기반으로 추론 과정을 수행하고, 사용자가 원하는 결과물을 생성한다. 즉, 텍스트와 이미지는 서로 다른 데이터처럼 보이지만 AI 모델 내에서는 모두 숫자 데이터로 통합되어 처리된다. 그러나 디퓨전 모델의 특성상, 초기 노이즈 패턴이나 인간이 입력하는 프롬프트 내용이 조금만 변경되어도 결과물이 달라지는 현상이 발생한다. 이는 디퓨전 프로세스의 유연성과 창의성을 보여주는 동시에, 일관된 결과물을 요구하는 작업에서는 추가적인 제어가 필요하다는 점을 의미한다.
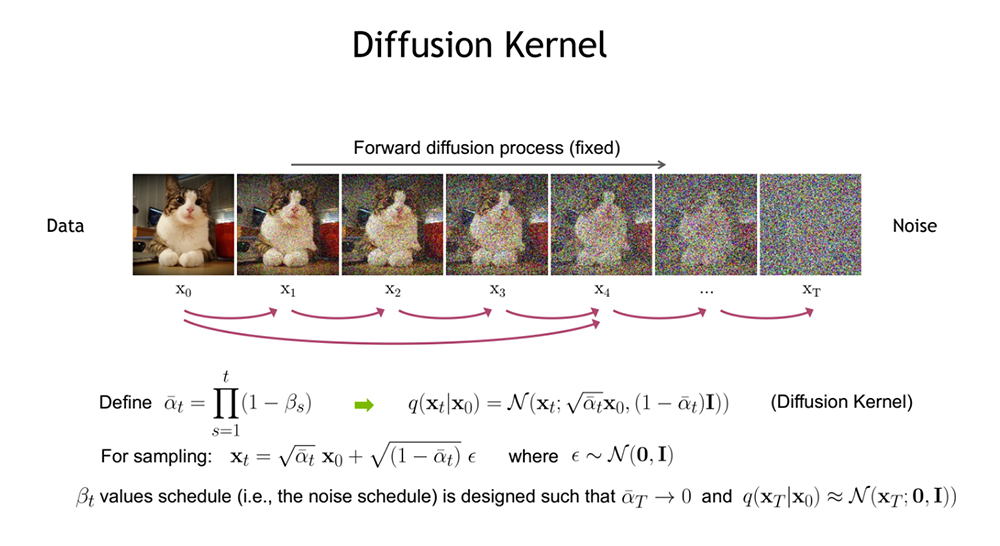 디퓨전의 계산 과정
디퓨전의 계산 과정
연속적인 인물 이미지를 구현해주는 기술들
친구나 가족에게 내가 상상하는 인물의 외형을 문장으로 묘사해보자. 같은 설명을 하더라도 사람마다 다른 형태를 떠올릴 것이다. 이는 추론 과정이 각자의 기억, 경험, 자신만의 데이터에 기반하기 때문이다. 디퓨전 프로세스에서도 비슷한 현상이 발생한다. 프롬프트는 텍스트로 이루어진 지시이며 AI는 이를 수학적 데이터로 변환해 추론한다. 이 때문에 초기의 노이즈 패턴이나 프롬프트가 조금만 달라져도 생성된 결과는 크게 달라질 수 있다. 인간이 같은 설명을 들어도 다른 결과를 떠올리는 것과 마찬가지다.
그렇다면 일관된 결과를 얻기 위해서는 어떻게 해야 할까? 처음에 특정 인물의 이미지 데이터를 모델에 입력하거나 참조 이미지로 제공하면 이를 주요 가이드라인으로 활용해 더 일관성 있는 결과를 생성할 수 있다. 결과적으로, 이미지나 영상의 연속성을 강화할 수 있게 되는 것이다. 이 밖에도 ‘페이스스왑’ 기술을 통해 특정 인물의 얼굴 정보를 학습시키고, ComfyUI 서비스에서 FLUX 모델을 실행해 피부 톤, 머리카락, 표정 같은 세부 요소를 정밀하게 처리해 안정적이고 자연스러운 이미지를 생성하기도 한다. ‘PuLID’ 기술을 더해 인물의 얼굴 데이터를 디퓨전 과정에 적응시켜, 동일한 인물의 일관성을 유지하면서도 디테일을 놓치지 않는 결과물을 제공할 수도 있다.
또 다른 강력한 조합은 FLUX 모델과 함께 인물의 자세, 조명 조건, 표정 변화 등을 학습해 보다 유연하고 자연스러운 결과물을 제공하는 FLUX 기반의 LoRA(Low-Rank Adaptation, 머신 러닝 모델을 새로운 컨텍스트에 맞도록 빠르게 조정하는 기술)를 사용하는 방식이다.
 소이.랩의 AI 인플루언서, VIKI
소이.랩의 AI 인플루언서, VIKI
이미지에서 영상으로
일관성 높은 인물 이미지를 얻은 다음 단계는 이미지를 영상으로 변경하는 일. 이때 필요한 것이 다양한 생성형 AI 영상 서비스를 활용하는 방법이다. 이들 서비스는 대부분 이미지-투-비디오(Image-to-Video) 기능을 제공하며, 단순한 이미지를 자연스럽게 움직이는 영상으로 변환할 수 있다. 특히 런웨이 젠3, 클링 AI, 하이루오 AI는 놀라운 품질의 영상을 생성할 수 있는 서비스로 주목받고 있다. 이런 서비스들은 영상을 생성하는 데 그치지 않고, 사용자의 세부 요구 사항을 반영해 더 높은 품질과 정교함을 제공한다. 각 플랫폼이 제공하는 기능과 특징을 적절히 활용하면 정적인 이미지를 창의적이고 독창적인 영상으로 전환할 수 있다.
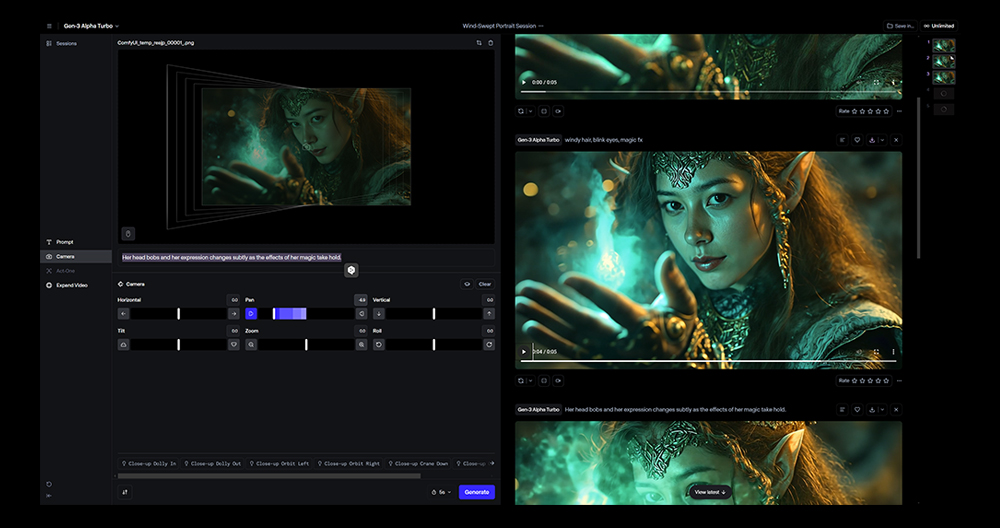 런웨이 젠3의 이미지-투-비디오 생성 화면
런웨이 젠3의 이미지-투-비디오 생성 화면
오픈소스 커뮤니티의 힘으로 빠르게 발전한 디퓨전 프로세스
여기 설명된 대부분의 기술들은 불과 몇 개월 사이에 빠르게 정립된 최신 기술이다. 이러한 기술 발전의 이면에는 오픈소스 커뮤니티 문화가 큰 역할을 했다. 오픈소스를 중심으로 한 협력과 공유는 기술의 성장을 가속화했으며 이는 한 회사나 조직이 이루기 힘든 집단 지성의 힘을 보여주었다. 오픈소스 커뮤니티는 지속적인 기술적 혁신을 이루고 있으며, 이를 통해 다양한 프로젝트와 서비스가 탄생하고 있다. 빠르게 변화하는 기술 트렌드에 적응하고 최신 정보를 얻고 싶다면, 국내 커뮤니티 페이스북 ‘STABLE DIFFUSION KOREA’와 ‘MIDJOURNEY KOREA’를 찾아보는 것도 도움이 될 것이다.
생성형 AI는 단순히 기술적 도구를 넘어 콘텐츠 제작의 새로운 표준을 제시하고 있다. 이런 기술을 활용해 더욱 창의적이고 멋진 콘텐츠를 제작하는 것은 K-콘텐츠 창작자들의 몫이다.
글. 최돈현(soy.lab 대표, 스테이블 디퓨전코리아 대표)
이미지 제공. soy.lab