SBS 유튜브 채널에 제공되는 영상의 더보기 란에는 ‘해당 영상을 AI의 학습을 위해 사용하지 말 것’이 명시되어 있다. 해외의 경우 언론사를 포함한 미디어 전반에 자사 콘텐츠를 불법 활용하는 생성 AI에 대한 경계심이 높다. 이에 관한 해외 사례를 알아보고, 우리나라 방송 시장에 미칠 영향을 분석해본다.
해외 미디어의 움직임과 SBS의 AI 학습 금지 선언
Copyright Ⓒ SBS. All rights reserved. 무단 전재, 재배포 및 AI학습 이용 금지
지난 8월 30일 SBS는 모든 콘텐츠에 이 같은 내용을 적시해 달라고 사내 각 제작진에게 공지했다. 그날부터 SBS 홈페이지나 각종 포털, 유튜브 채널의 SBS 콘텐츠 맨 아래에는 위와 같은 문구가 첨부되기 시작했다. ‘SBS의 콘텐츠를 AI 학습에 이용하려면 허락을 받고 사용하라’는 원칙을 외부에 고지한 것으로, 국내 방송사 중에서 ‘AI 학습 이용 금지’를 선언한 것은 SBS가 처음이다. 앞서 한국일보와 중앙일보, 동아일보, 한국경제 등 일부 신문들도 ‘AI 및 대량 크롤링 방지’ 약관을 신설했다. 생성형 AI와의 ‘전쟁’에 대비해 회사별로 원칙을 선언하고 진지를 구축하기 시작한 셈이다.
생성형 AI가 언론사 데이터를 학습하면서 발생하는 저작권 논란은 올해 초부터 시작됐다. 지난 2월, 월스트리트저널 기자 출신이면서 데이터 추적 플랫폼 어플라이드액셀(AppliedXL) 최고경영자인 프란체스코 마르코니 (Francesco Marconi)가 챗GPT에게 어떤 언론사의 뉴스 콘텐츠를 기반으로 학습했는지 물었더니 챗GPT는 “로이터, 뉴욕타임스, 월스트리트저널, CNN 등 20여 개 매체의 뉴스를 활용했다”고 솔직하게 털어놓았다. 마르코니의 고발 이후 월스트리트저널은 즉각 챗GPT 개발사인 오픈 AI를 상대로 소송을 준비하기 시작했다. 미디어 유관협회들도 목소리를 내기 시작했다. 세계신문협회(WAN-IFRA, World Association of Newspapers)는 ‘글로벌 AI원칙(International AI Principle)’ 초안을 마련해 각국 언론에 공유했고 국경없는기자회(RSF, Reporters Without Borders)도 지난 7월 27일 ‘미디어 AI 준칙’을 마련해 발표했다. 일본신문협회 역시 일본잡지협회, 일본사진저작권협회, 일본도서출판사협회와 공동으로 ‘생성형 AI에 관한 성명’을 발표했다.
미디어 관련 협회들이 발표한 준칙이나 성명의 형태는 달라도 핵심은 하나다. 생성형 AI 시스템이 미디어의 지적 재산을 무분별하게 도용하는 것은 비윤리적 행위이며 언론사 비즈니스 모델을 침해하는 만큼 ‘보상’을 지급해야 한다는 것이다. 생성형 AI가 고품질의 결과물을 생성하는 데 뉴스 데이터는 가치가 크다. 팩트를 기반으로 중층적인 게이트키핑1)을 거치며 정치·경제·사회·문화·과학·스포츠 등 다양한 주제를 폭넓게 다루는 콘텐츠는 뉴스밖에 없기 때문이다. 콘텐츠에 대한 보상을 위해 각 언론사는 생성형 AI 비즈니스 기업들과 개별 협상을 벌이기 시작했는데, 파이낸셜타임스는 “뉴욕타임스나 가디언 등 언론사들이 각각 적어도 한 곳 이상의 기술 기업과 논의를 진행하고 있다”고 보도했다.2) 언론사들이 기술 기업들에 제시한 금액은 연간 500만 달러(약 64억 7,500만 원)에서 2,000만 달러(약 259억 400만 원)가량이라고 파이낸셜타임스는 전했다. 이런 가운데 지난 7월 13일 AP통신과 오픈 AI가 뉴스기사 사용 등에 관한 라이선스 계약을 체결하면서 언론사와 빅테크 기업 간의 저작권 계약 첫 사례가 나왔다.3) 구체적인 계약 조건은 공개되지 않고 있지만, 데이터 사용량에 따라 얼마를 지급한다는 사용료 개념이 아니라 기술과 콘텐츠를 맞교환하는 협업 계약 형식으로 파악되고 있다.
-
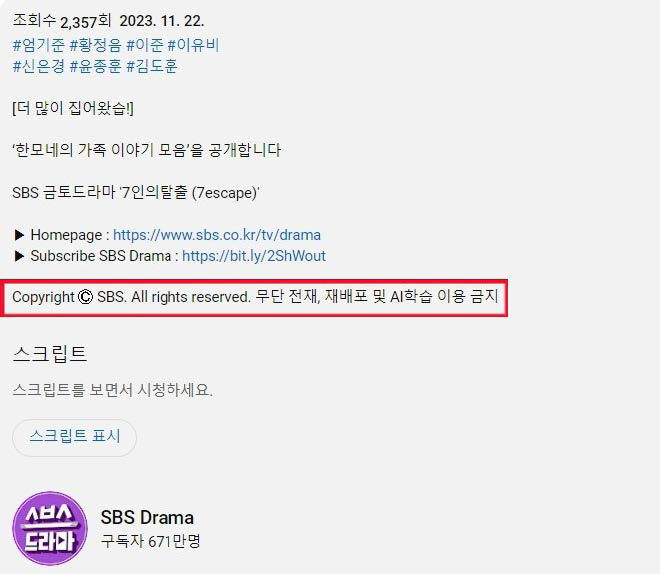
뉴스뿐 아니라 SBS 드라마, 예능 클립의 더보기 란에도 위와 같은 문구가 삽입돼 있다.
출처: SBS Drama 공식 유튜브 채널
국내 미디어 상황은?
국내에서는 지난 8월 24일 네이버가 자체 초거대 인공지능 ‘하이퍼클로바X’를 공개하면서 본격적인 논란이 시작됐다. 하이퍼클로바X는 뉴스 50년 치와 블로그 게시글 9년 치에 달하는 고품질 한국어 뉴스 데이터를 학습했다고 네이버는 밝혔는데, 이를 위해 개별 언론사들의 동의를 구하지는 않았다. 대신 네이버는 하이퍼클로바X 출시를 5개월 앞둔 지난 3월 약관 개정을 통해 ‘서비스 개선, 새로운 서비스 개발을 위한 연구를 위해 직접, 공동으로 또는 제3자에게 위탁하는 방식으로 정보를 이용할 수 있다’는 신설 조항을 제시하려 했지만 언론사들의 반발로 무산됐다. 복잡한 보상 문제에 대비해 ‘연구 목적’으로 사용한다는 주장을 펴겠다는 것이다. 이에 대해 신문협회는 “정당한 권원 없이 뉴스 콘텐츠를 AI 학습에 이용하는 것은 언론사의 저작권을 침해하는 행위로 공정한 이용에 해당하지 않으며, 뉴스 콘텐츠 활용에 대한 보상이 필요하다”는 공식 입장을 발표했다.4)
관건은 공정 이용에 해당하느냐다. 구글의 글로벌 담당 사장인 켄트 워커(Kent Walke)는 인터뷰에서 “AI 모델은 기본적으로 외부의 모든 정보를 학습한다. 학생이 도서관에 가서 책을 읽고 글을 쓰는 법을 배우는 것과 비슷하다”고 주장했다.5) 공정 이용에 해당되므로 저작권료를 내지 않아도 된다는 것이다. 미국에서 시작된 저작권 관련 소송이 10건이 넘지만 피고 측의 구체적 주장은 아직 나오지 않은 상태다. 국내 AI 개발사들 역시 ‘토종 AI 발전을 위해’ 공정 이용을 주장한다. 기존 저작권법에 공정 이용 조항(35조 5항)이 있는데 이를 보다 명확하게 규정해 AI 학습에 데이터를 사용하게 해 달라는 요구다. 공정 이용에 해당하는지 아닌지에 대한 법정 다툼의 결론이 나오기까지 국내외에서 상당히 오랜 시간이 걸릴 것으로 보인다.
정부와 입법기관들도 움직이고 있다. 미 의회조사국(CRS, Congressional Research Service)은 생성형 AI 시스템이 저작권을 침해할 가능성이 높다는 의견을 내놓았고, 미 특허청(USPTO, United States Patents and Trademark Office) 역시 생성형 AI의 시스템이 사실상 작품 전체 또는 상당한 부분의 복제를 수반할 것으로 보고 저작권자의 독점적인 복제권을 침해할 수 있다고 지적했다.6) EU 의회는 학습데이터 공개에 관한 사항을 AI 법에 넣어야 한다고 제안했는데, 저작권에 의해 보호되는 데이터를 이용했을 경우 그 사실을 상세하게 공개하라는 내용이다.7) 저작권자 입장에서는 학습 데이터로 자신의 저작물이 사용됐다는 사실을 입증하기 어려우니 미리 학습 데이터를 공개하라고 요구하는 것이다.
국내에서도 2021년 9월 국가 인공지능 경쟁력 강화를 위한 ‘인공지능 최고위 전략대화(AI Stratege Summit)’가 출범해 AI 학습의 저작권 침해 문제 논의를 시작했고, 지난 2월에는 문화체육관광부가 생성형 AI 기술 변화에 대비한 문화적·제도적·산업적 기반을 마련하기 위한 3개의 워킹그룹을 꾸려 9월까지 논의를 진행했다. 이와 관련해 정부산하 저작권위원회는 최근 열린 ‘서울 저작권포럼’에서 “공정 이용 적용 여부가 불명확한 상황에서 타인의 권리를 침해하지 말 것”을 요구했다.8) 생성형 AI의 저작권 침해 문제와 관련한 정부의 첫 입장이 나온 것이어서 주목된다.
협상에 고려할 점 많아
미디어가 보유한 콘텐츠의 사용 문제를 놓고 시작된 생성형 AI와 미디어 간의 샅바 싸움은 포털 초기 뉴스 콘텐츠 제공 논란을 떠올리게 한다. 미디어 입장에선 콘텐츠를 제공하는 대가로 정당한 보상을 받아야 한다는 생각은 분명하지만, 보상이 충분치 않다며 콘텐츠 제공을 거부할 경우 소외될지도 모른다는 두려움이 있다. 포털에 검색의 주도권을 뺏긴 후 방문객을 잃은 각 언론사 입장에서는 생성형 AI가 데이터를 몽땅 가져가면 다이렉트 링크로 언론사를 방문하는 이용자가 더욱 줄어들 수도 있다는 걱정이 클 것이다. 포털에 뉴스를 제공하면서 ‘헐값 협상’ 한 것을 두고두고 후회 중인 언론사들로서는 다가오는 생성형 AI와의 보상 협상에선 두 번의 실수는 범하지 않겠다며 벼르고 있지만 대응 전략이 마땅치 않은 게 현실이다. 그래서 언론사들의 집단적 딜(deal) 형태가 효율적이라는 의견도 있다. 또는 이미지, 영상, 텍스트 등 다양한 데이터가 결합된 ‘멀티모달 데이터’를 중심으로 거래하는 방안이나, 언론사 각 사가 페이월(Paywall, 기사 유료화)을 만들어 데이터 값을 받는 방안 등도 거론된다. 9)
하지만 보상이 전부일까? 보상을 넘어 더 중요한 것은 ‘어떻게 사용할 것인가’다. 생성형 AI의 활용이 가져올 수 있는 수많은 부작용은 벌써부터 딥페이크, 가짜 뉴스 같은 형태로 현실화하고 있는데 부작용 방지에 대한 논의는 진영간 싸움으로 변질되고 있다.
-

AI로 만들어진 딥페이크 영상을 이용한 가짜 뉴스는 이미 여러 나라에서 문제로 지적되고 있다.
출처: SBS 뉴스 공식 유튜브 채널
그래서 언론사들과 빅테크 기업 간의 협상은 한 차원 높게 진행될 필요가 있다. 정당한 보상은 기본이고 여기에 더해 미디어와 기술이 상생할 수 있는 방향으로 논의되어야 한다. 일부 전문가들은 생성형 AI의 뉴스 콘텐츠 이용 원칙부터 만들 것을 제안하기도 한다.10) 생성형 AI의 활용은 앨빈 토플러의 ‘제3의 물결’을 넘어서는 ‘제4의 물결’로 정의해도 될 만큼 상상할 수 없는 큰 변화를 가져올 것이기 때문에 그 논의는 인류의 지적 진보를 위한 것이어야 한다.
- 1)
- 기자나 편집과 같은 뉴스 결정권자가 뉴스를 취사선택하는 과정을 말한다.
- 2)
- <AI and media companies negotiate landmark deals over news content>, https://www.ft.com/content/79eb89ce-cea2-4f27-9d87-e8e312c8601d
- 3)
- Gerrit De Vynck, <OpenAI strikes deal with AP to pay for using its news in training AI>, Washington Post, 2023.07.13., https://www.washingtonpost.com/technology/2023/07/13/openai-chatgpt-pay-ap-news-ai/
- 4)
- 이세원, <신문협회, 네이버·카카오에 AI의 뉴스저작권 침해 방지 요구>, 연합뉴스, 2023.08.22.,https://www.yna.co.kr/view/AKR20230822113400005?input=1195m
- 5)
- Gerrit De Vynck, <AI learned from their work. Now they want compensation>, 2023.07.16., https://www.washingtonpost.com/technology/2023/07/16/ai-programs-training-lawsuits-fair-use/
- 6)
- 글로벌과학기술정책서비스, <미국, 생성형 AI와 저작권법에 관한 보고서 발표(Generative Artificial Intelligence and Copyright Law>, 한국과학기술기획평가원, 2023.05.11.,https://now.k2base.re.kr/portal/trend/mainTrend/view.do?poliTrndId=TRND0000000000050788&menuNo=200004&searchCate=&searchNate=002&searchSubj=&sdate=&edate=&searchCnd=1&searchWrd=&pageUnit=10&pageIndex=4
- 7)
- 윤종석, <“챗GPT 사용한 데이터 저작권 표시해야”…EU, 첫 AI 규제 추진>, 연합뉴스, 2023.04.28., https://www.yna.co.kr/view/AKR20230428029900009
- 8)
- 이태수, <AI 저작권 관련 활용 가이드 첫 공개…“타인 권리 침해 않아야”>, 연합뉴스, 2023.10.26., https://www.yna.co.kr/view/AKR20231026139300005?input=1195m
- 9)
- 오주환, <“AI의 뉴스 학습은 ‘공정이용’에 해당 안된다”>, 국민일보, 2023.11.14., https://news.kmib.co.kr/article/view.asp?arcid=0924330028&code=13110000&cp=nv
- 10)
- 최성진, <뉴스로 학습하는 AI에 “교재비는?”…언론계-테크기업 샅바싸움>, 한겨레, 2023.10.04., https://www.hani.co.kr/arti/society/media/1110724.html
-

-
조성원
SBS 보도본부 기자로 일하면서 8뉴스부장, 경제부장 등을 지냈고 유튜브 채널인 ‘비디오머그’에서 유튜브 콘텐츠도 제작했다. 현재는 SBS의 ESG 정책을 담당하면서 동시에 연세대학교 겸임교수로 30년 기자 생활에서 경험한 방송 저널리즘, 방송산업 이슈를 학부생들에게 가르치고 있다.